In the ever-evolving landscape of technology, data products have emerged as the cornerstone of innovation, driving billions in revenue for tech giants and reshaping industries. As we transition into a new era focused on business value rather than mere data pipelines, it's crucial for data professionals to understand and adapt to this shift. This article explores the intricate world of data products and their significance in modern data engineering.
The Symbiosis of Machine Learning and Data Engineering
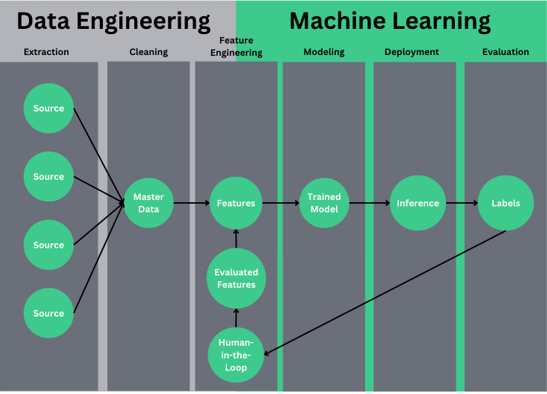
The line between Machine Learning (ML) and Data Engineering is increasingly blurred, creating a symbiotic relationship crucial for AI-driven solutions. While ML focuses on developing algorithms and models to extract insights from data, Data Engineering ensures the data pipeline is robust, scalable, and delivers high-quality data for analysis.
Feature engineering stands out as the nexus where machine learning engineers and data engineers collaborate to create magic. This critical step is essential for improving model performance in production, especially for complex use cases like cybersecurity.
Defining Data Products
Data products transcend traditional data pipelines and datasets. They are characterized by:
- User interfaces that visualize data typically confined to data lakes
- Access points and APIs beyond standard SQL and Spark interfaces
- Feedback loops that incorporate human input and improve based on high-fidelity feedback
Real-World Applications
- Facebook's SUMA (Single User Multiple Accounts): This system uses ML to determine if multiple accounts belong to the same person, employing human labelers for uncertain cases.
- Airbnb's Host Behavior Prediction: ML systems identify potentially abusive hosts by analyzing signals about hosts, guests, and reservations.
These examples illustrate how data products form the backbone of big tech operations, extending beyond recommendation systems to critical business functions.
Essential Skills for Data Engineers in the Era of Data Products
As data engineers become central to data product development, several key skills are crucial:
- Data Quality Management: Cleansing and creating high-quality data remains fundamental.
- Predictive Modeling:
- Understanding statistics and machine learning concepts
- Linear vs. non-linear effects
- Algorithms: XGBoost, Decision Trees, Random Forest
- Mastering the five types of features:
- Quantitative: Continuous and Discrete
- Qualitative: Nominal, Ordinal, and Binary
- Closed-Loop System Design:
- Developing front-ends for human-in-the-loop labeling
- Creating back-ends for data logging to systems like Kafka
By honing these skills, data engineers can position themselves to make significant contributions to large-scale ML systems and data products, potentially leading to lucrative career opportunities.
The Future of Data Engineering
As we move forward, the role of data engineers will continue to evolve. Those who can bridge the gap between traditional data engineering and machine learning will be at the forefront of innovation. By focusing on creating value through data products, engineers can drive business outcomes and play a pivotal role in shaping the future of technology.